
We’ve all seen people selling expired domains, PBN links, and Web 2.0 links for crazy amounts of money. When everything boils down to it though, you’ll find that most people paid a mere TEN dollars for that domain that they’re selling for 10, 20 and even 30 times that amount. The links they’re renting out for $10/mo cost them only ten dollars to get started. Would you believe me if I told you that you could learn how to do exactly what they’re doing, by investing a few hours of your time and picking up some fairly cheap tools?
In this guide I’m going to teach you guys how to scrape your own expired domains using a few common tools. This method is fairly Blackhat, but I prefer doing it myself if possible rather than paying some cranky vendor hundreds of dollars for links I can get myself. I trust my links more than other people’s links as well. I am in total control of my PBN, and you can be too.
Without further ado, let’s get into how you’re going to scrape your very own domains.
The Background
For this guide you’re going to need a few things:
- Ahrefs/Majestic SEO
- Scrapebox
- Time – A few hours
- A Basic, Working Knowledge of SEO
- Proxies
- Notepad++
The first thing you’re going to do is generate your seed list of keywords. You can come up with this yourself or use a few options to generate your keyword seed list. Personally I use two different free tools to find a good seed list in your niche.
UberSuggest suggests keywords based on whatever you input. For this entire guide we’re going to use “tattoos” as an example. Plug in whatever your main keyword is into UberSuggest and pick out a good amount. I go for 50-100, but you can pick as many as you like.
I did a quick run for “tattoos” and it returned 310 other keywords for me to use in my list –
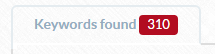
This would be enough keywords for the method we’re going to outline in this guide, but if you don’t find enough for some reason, you can also use another tool to find more keywords by our friends at Google.
Google Keyword Planner
We all know of the famous keyword planner for finding new keywords, but in this guide you’re going to use it for something different than what you’d usually do.
Step 1
Search your main keyword in Google and find a big site that’s ranking for a ton of keywords. I found http://tattoodo.com for example. The site is completely relevant to our main keyword which you want it to be, don’t go inputting the Tattoo Wikipedia page for example – You want a 100% relevant domain.
Step 2
Go into Keyword Planner and input the website you found as the “landing page” URL –
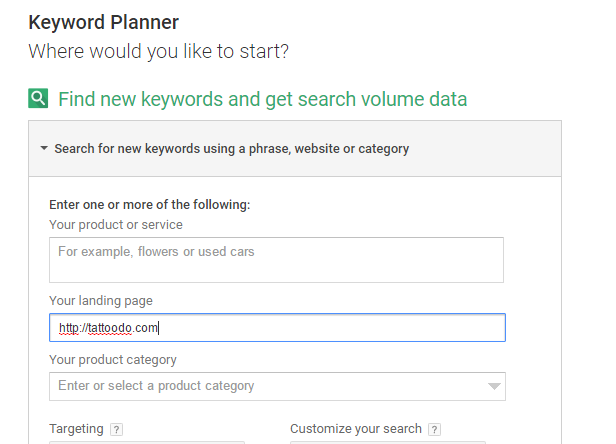
Scroll down and hit “get ideas”.
From there you’re going to get a ton of keywords related to your niche. There will be “ad groups” you can select if you want to be picky. For this example we want a huge list – the larger our root list, the more expired domains we’re going to find.
Step 3
Hit “download” and you’re going to get a huge Excel file. I found 950+ keywords just from this one search.

Step 4
Weed out any root ideas that don’t really pertain to your niche. I like to run this screening process before actually beginning my search to weed out anything irrelevant. I didn’t really find anything irrelevant in this search, but you may find a few seed keywords you don’t want to waste your time with.
Now that you have a real, concrete list, it’s time to start scraping!
The Scraping Process
The entire scraping process can be pretty drawn out and technical for those not used to using certain pieces of software so make sure you’re following every instruction or you’ll likely end up messing up the process.
Preparation
First we have to add quotations around our search terms so we will be searching for the exact keywords. To make this process quicker (and less resource intensive on my PC), I am just using the list of 200+ good keywords UberSuggest provided me. If I wanted to conduct a more extensive search, I would use the total list of over 1,000 I pulled off both tools.
Take whatever list you’ve come up with and want to test, and plug it into Notepad++ (A free download every SEO should have and use) by just copying + pasting it.
Now we want to add the quotation marks.
Hit CTRL+F (to find + replace), and search for “^”. Next, enter a quotation mark in the “replace with” field, and don’t forget to check the “regular expression” tab at the bottom. Here’s what this looks like when completed:
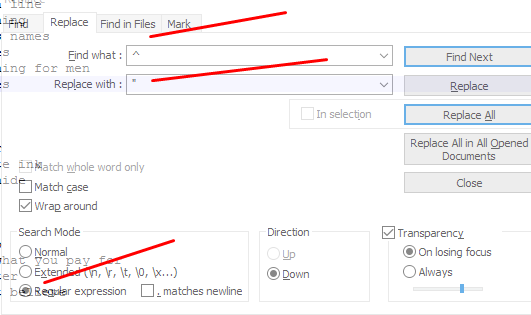
To add quotation marks at the end, simply replace the “^” with a dollar sign like so.
![]()
Now you’re all set to go – almost.
Note: you cannot use the standard MS Notepad for this.
Then save your new keyword list, in my example I’ve saved it as “tattoosScrapebox”.
If you want to just add quotes right in Scrapebox, you can do so as well but I prefer to have a root list on hand that I can plug in –
Making Our Search Query Complete
One of the last steps of the preparation phase will be to search by date. We want to find POWERFUL expired domains. This means we want to look for older domains. Obviously, we could find some new sites that are highly authoritative, but for the most part an older domain will work better. Google search queries don’t use your typical date format, they use the Julian date system. If you don’t want to go through trouble of figuring out exactly which dates to pick and getting the number yourself, just use this query that will search from April 2002, to April 2012.
“Links” daterange:2452376-2455298
As crazy as this query looks, it’s going to search for websites that include the query “links” from April 2002, to April 2012, that are also relevant to our seed keywords that we just found.
You have to save the query to a .txt file so do that quickly in Notepad++ and import it into Scrapebox. It will ask you to merge it with your keywords which you have to do.
We’re finally here… it’s time to scrape!
Make sure you’re using at least 10-20 private proxies when conducting the search, especially if you have more than 100 keywords, or you’ll get captcha blocked by Google. In this example I’m using 200, but I’m going to stop the search once I find a decent amount of domains. Typically I’d leave this up on a VPS overnight searching thousands of keywords but I didn’t want to wait overnight to write this blog post.
Now all you have to do is hit that juicy button –
![]()
Remember to ONLY search Google. Don’t select any other search engines or the query we’re inputting may not work properly.
This process may take a few minutes, or it may take a few hours depending on how strong your internet connection is, the speed of your PC, the number of keywords and the quality of your proxies.
For the example I’m just going to use one root keyword. Typically I would use many more but we’re going to be looking at the process, not how to scale the process. This will show you what just one keyword can do for you.
At this point you’re going to get a huge list of total links. You’ll notice some sites pop up hundreds of times. Scrapebox has something simple for this. For my example, this spit out:
![]()
Hit “remove/filter” and remove the duplicate URLs AND domains. This will weed down your list quite a bit, but we aren’t done yet.
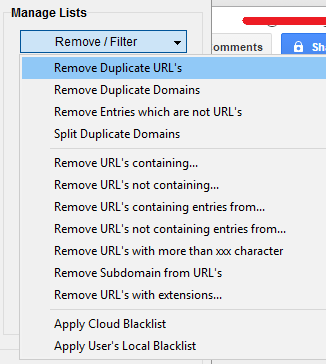
Now my list of 468 is down to 105. We’re trying to find huge resource pages, and although if you have a smaller list you’re going to be able to easily remove the bad links out on your own, it’s a huge pain in the ass on a large scale. I don’t like to miss out on great resource pages so I hire a VA to manually do this process. By using certain queries to remove certain links, I can miss out on links that would typically be missed by everyone else.
Our goal is to find the domains that slip through the cracks of what everyone else is already doing. If we do exactly what they do, we’re going to miss out on links. For example, if you removed every domain on your list that didn’t include the word “links”, you’d be missing out on blogroll posts, resource pages, and more.
You can weed out things like “links”, “blogroll”, “resource”, and more and compile those words into your list, or you can manually find the domains. I prefer to weed out all duplicate URLs and subdomains and then just go to town on a huge list. This is what I did at first to find domains and if you’re just starting off you might enjoy doing it too. If you don’t, feel free to skip this step and use a few search queries and delete the rest of the relevant domains.
Now that you have your finished list (I have 12 domains), you’re going to paste them into Scrapebox and use the Link Extractor. You can also use XenuSleuth for this process if you’re more familiar with that free tool. You can find the Link Extractor under “addons” and it’s completely free.
Now your list is going to get bigger as we’re going to actually scrape the lists of links we found for relevant, expired domains.
Bonus Step: At this stage, I would suggest taking your root list (if it’s small) BEFORE scraping and mass-checking the DA/PA with MozCheck. You might find that you only have terrible domains, in which case you’d restart from the beginning.
Whether you decide to use the larger list or trim yours down even more is up to you. It’s time to use the Link Extractor. Load it up, input your URLs, and make sure you hit “external” at the bottom so we can grab those sweet, juicy links.
Now you’re going to get a huge list of links after an hour or so depending on how large your search is. Trim the URLs down, and we’re almost ready to go.
Remove all the duplicate domains/URLs again if you’re looking for expired domains.
Pro Tip: If you want to find expired Web 2.0’s, don’t get rid of duplicate domains or you won’t find any. You can also separate these into two lists at this point, Web 2.0’s and expired domains. Just search your huge list for “Tumblr”, “Blogspot”, “Wordpress”, etc and remove any domains with an extension and you can check them later on.
Once you trim your list down a bit more, it’s time for the final step using Scrapebox, checking domain availability. This couldn’t be easier. I’ll let the image do the talking.
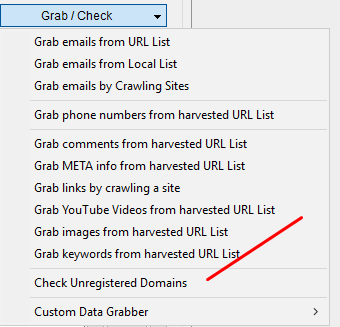
Export the domains and you’ll be good to go…almost. You have a list of relevant domains that all appear on old, aged resource pages. The domains are even available for registration…So what is left to do?
You don’t want a useless domain that won’t pass any juice.. If you don’t have a paid account of Majestic SEO, doing this process on a huge scale becomes a pain in the ass but it can be done manually.
Shameless Plug: You can also use BHC’s tool available to members to easily bulk check the domains you scrape at http://tools.blackhat.community/bulk-maj-check.php .
You can then sort the domains by any number of metrics you want, referring domains and referring IPs is the one I use the most and then correlate with TF/CF or just have a VA manually look through the link profiles to find good domains.
Avoid foreign anchors, spammy anchors, pharma anchors, and more. Use common sense – if the links don’t fit the site, don’t buy it.
Bonus
If the anchor text already reflects certain keywords in a specific niche, you might be able to turn that domain around and use it as a money site instead of using it as a PBN domain – Just a piece of advice. I’ve made some of my best money sites off of domains I found while looking for expired domains.
The Last Step.. I Swear
The last thing we’re going to do – because we’re extra cautious, is to check the domain out to see its past. If only we could do this with girls before dating them.
Head over to https://archive.org/ and see if the site looks like it was previously used for something dodgy. If you go back in time and find that the website was always used for a just cause, you have a winner. Register the domain before somebody else does. If the domain seems to have been used for something a bit shady (such as a PBN or has a bunch of random Chinese writing all over it) then write it off.
You really have to gauge this part yourself though. What is too far? Is it worth taking a $10 risk that your domain may never index? That part is up to you. Personally, as long as the anchor text matches up with what the Wayback Machine shows me, I’m all in on the domain.
If it doesn’t work out, I’m out ten bucks.. That’s a few cups of coffee, or 1 at Starbucks.
Conclusion
Hopefully you guys enjoyed this guide! I guarantee that if you take the time to use this method, you will find domains. Do it a few times manually to really understand the process, and then scale it just like everyone else does. Use a VPS. Hire VAs. Make something about the process your own and you can make a living solely off this. I know people who do it, and you can too.
“We must learn to walk before we can run.”
Thanks For Reading
Thanks for reading and don’t forget to drop a comment with your thoughts on expired scraping below, as well as join my FREE 7 day SEO email course.






